At the completion of year 11 exams, students at my school are expected to return for 4 weeks to “begin year 12”.
Rather than set a bunch of individual assessments, or run a formal test only for students to disappear on 8 weeks holidays, I prefer to work on a collaborative multiplayer game – a different one each year – which is closer in development approach to a game jam than a traditional cycle or scrum.
Prototype: Chestral
The first year we did this, we created Chestral – a simple game which set the structure for the two subsequent projects.
The goal was to have a “main screen” server which presented the graphics, progress etc for all players to look at, while the clients connecting to the server would be coded by individual students and would effectively be minigames.

The implementation is very similar to the Jackbox Games model – everyone looks a one big screen while each having their own little ones. In Chestral’s case, the actual game itself was designed to be like an MMO raid boss fight.

Chestral was overly simplistic in its rules for clients – most players would just focus on their client’s minigame and let the “raid leader” – the Maestro – handle the encounter.
It was still fun, and there was an enormous depth and variety of learning (client/server models, APIs – even getting the hardware to run the clients on the day was a huge exercise) and excellent engagement, as all the 11s turned up on our school’s showcase day to set up and exhibit the game, despite it being their first day of holidays.
Terminal:Exploit
My next year 11 class was working in the new Computer Science syllabus – which is far more demanding (particularly with regards to programming) and this meant a higher standard of complexity could be expected from the clients they produced.
Terminal:Exploit was conceived as a game structured around the cyber security and network protocol concepts covered in the course. In contrast to the cooperative nature of Chestral, Terminal:Exploit pits two teams of four against one another.

We kept the same overall client/server structure (one big screen, each client has small screens) but took the lessons of Chestral’s implementation (don’t design your clients to run only on the developer’s hardware!) and specifically developed the clients to
- All have identical hardware/library requirements
- Be purely text based (hence, terminal)
- Be designed for specific, available hardware (SOE laptops provided by the school)
Some of the more ambitious students pushed for clients which were Godot implementations, rather than terminals, but these were not able to be integrated in time.
T:E is a more exciting and more complete game experience when compared to Chestral; the learning curve is steep and the concept is so abstract as to frighten off prospective players, but once you’ve played a round or two, you get the hang of it and it becomes a very compelling team PvP experience.
The game objective is simple enough – either steal all your opponents’ keywords before the game timer expires or have more points than the opposing them when the timer does expire. Executing commands in one of the terminals to “connect” to your opponents allows you to discover and claim their keywords.
A typical client device will look like this:
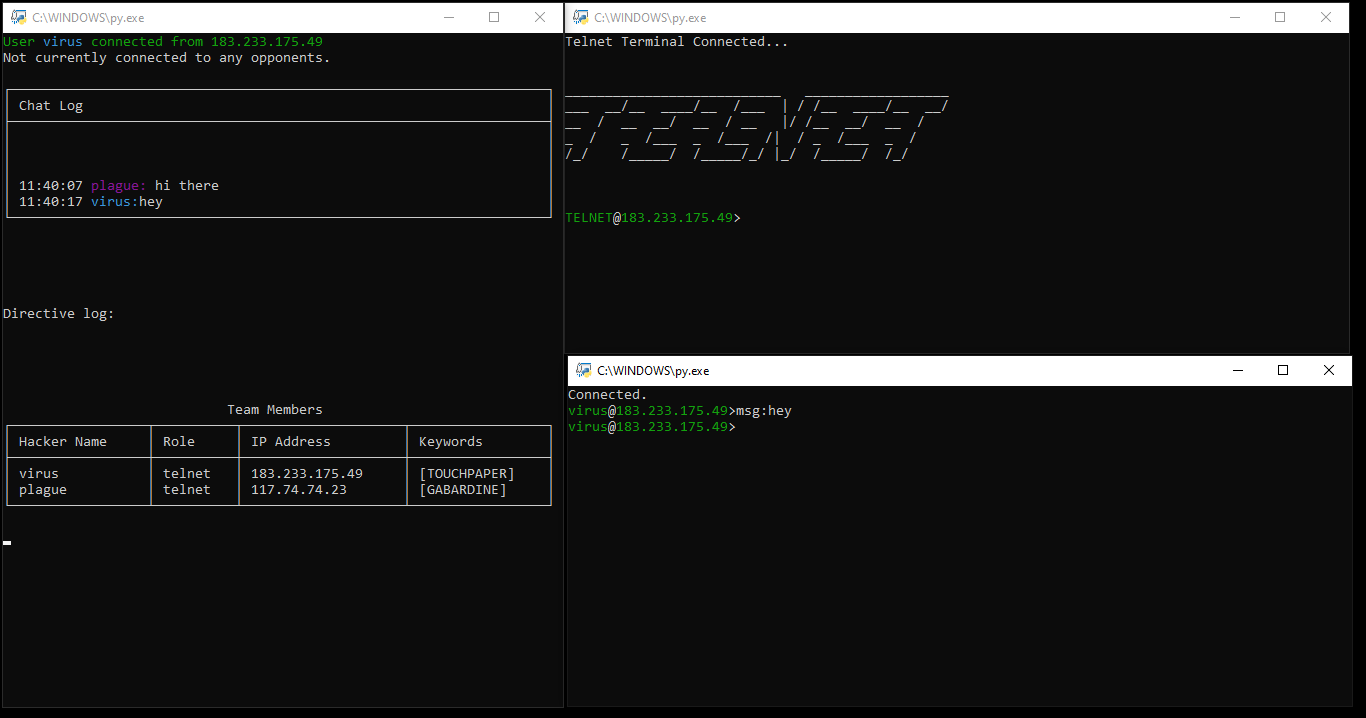
There are actually three terminals on the screen for each client!
It would be technically quite possible to combine the functionality of all three terminals into one – but this would require a more aggressive use of threading, which I wanted to avoid, and make the separation of tasks more complex (a single student worked on the command terminal in the bottom right, two students worked on the status terminal in the left hand side and each game terminal was different depending on the client mode).
Clockwise from the left side terminal:
- Status terminal. Non-interactive, this terminal provides a 5 line chatlog for your team, current directives (instructions for use with the game terminal) a table of team members and keywords, and, once the game starts, a table of opponent data as it is discovered by your team.
- Game terminal – in this case, telnet. In theory, each game terminal was intended to be a new protocol – the player must manage their “server” to earn points and intel to be used in the wider game. In practice, we only managed to get two game modes running – telnet and SMTP. Partially/mostly complete were FTP and SSH terminals, along with more free form/less terminal-like modes UDP/TCP (simulating packet processing, similar to a firewall) and YTOS (simulating scheduling on an operating system).
- Command terminal. The command terminal is a general purpose thin client – it allows players to communicate with their team as well as move keywords around and use abilities. In addition, the command terminal is the terminal from which a player can “connect” to an opponent’s game terminal.
Much work was done to ensure these client terminals would run on the provided systems and automatically size to fill the screen.
The majority of the processing was performed server side – this was a double edged sword. It allowed for fairly rapid development of the status and command terminals, but necessitated that the game terminals have their logic split between the client and server. Students either struggled to create code for the server to handle their game terminal or simply left it to me entirely. This was definitely a factor in the number of incomplete game terminals; on the other hand, the “connections” made from the command terminals simply could not have actually gone through to game terminals without making client development significantly more complex. I’m chalking it up as a wash; the concept behind T:E didn’t lend itself well to this specific aspect of student development, and no “best” approach exists.
Fans of Friends at the Table might notice the keywords are a little familiar – they are taken directly from the finale of Partizan (and its soundtrack). In fact, on showcase day, we used the Partizan soundtrack (from the incomparable Jack de Quidt) as music for the game. Slow, menacing, disorienting – perfect.
Of Aesthetics
My original vision for T:E was to recreate the vibe of 70s and 80s terminals – often two-tone black background affairs with either green or orange text. The conceit is that the game is set in a dystopian future, advanced hardware and software is either lost or inscrutable – leaving rival gangs to manually manage their own servers in a deiselpunk wild west Internet.
I’m happy with the overall impression the game makes – it looks a lot less accessible than it is – which might seem like a totally backwards intention, but for me, that is the hacking scene of the 70s and 80s.
In order to play, you need to refer to a printed manual, a feature I find to be as delicious as it is absurd in the 2020s.
Merits as a Game
Is this a good game?
I think so – it’s generations ahead of Chestral in complexity and user satisfaction. Certainly, the next year’s group of students, once they got the hang of the interface, were excited to play it more than a few times.
That said, its incompleteness is its downfall – given the limited number of game terminals and the lack of progression for each one (we had envisioned a skill tree of sorts to allow each player to fill different roles more effectively), the replayability is limited. I anticipate after around a half dozen games, the shine will have worn off and players won’t want to come back.
Merits as a Learning Tool
Does this game, in and of itself, have educational value?
I think so – I find that students (and adults) generally have a fear of the terminal, often not having any idea of how to use a command line interface at all. T:E creates a motivation to build familiarity with the interface and there’s some value there.
Do players learn much about the protocols? Probably not – many liberties were taken when conceiving of the game loops for each terminal and so those skills don’t particularly translate over. That said, the SMTP game requires players to literally type SMTP protocol commands to send an email, so I guess that’s something? They learn how awful SMTP is?
There’s also some value in the basic concept of using the command terminal to connect to another player’s IP address and port (both completely fake on the backend – each terminal connects only to the server) so this might assist in understanding the concept of devices having IP addresses as well as ports for individual services.
Beyond that, communication and collaboration need to be used to have a successful team – so don’t rule out those “soft skills” as benefits.
Merits as a Project
This project pushed my students more than Chestral, so in that sense it was successful.
The abstract nature of the concept was a huge barrier to students starting – they needed to see the concept in action to grasp what was required of them, which reduced the amount of productive working time.
Students all used git repositories to manage and share code, which is an invaluable introduction to the concept of version control systems.
We pushed the idea of developing for a specific standard operating environment during this project and students were responsible for deploying and testing to this environment – which I believe to be worthwhile as it is an experience missing from a typical high school project.
And, as with Chestral, almost all students turned up to set up and demonstrate their project on what would otherwise have been their first day of holidays, so I think that speaks volumes to engagement and motivation for students.
Not an unmitigated success, but certainly a project of which I’m very proud.